6 min to read
Caching - stuff you have always wanted to know but were afraid to ask
I was having a recent chat about caching with someone. It was interesting enough for me to reflect on and add to my ruminations here in this blog.
The Basic Idea
Caching is all about performance. The basic idea is to avoid repeating a complex, input-dependent, stable operation- be it data manipulation, algorithmic computation or expensive calls over the network - by storing the results of the previous computation and returning the results from some kind of a caching repository using some key based on the inputs passed to this operation. The preceding definition probably has left you more blurry eyed than what you were when you first stumbled on to this page! Like Sherlock Holmes would say, there are certain singular points about caching that are of interest and hence would require further elaboration.
Input Dependent Complex Operation
I define a complex operation as something that would consume a lot of computing resources. These resources can be CPU resources or network bandwidth or anything else that is sparse and should not be used in a profligate way. This operation should be input dependent which means that every invocation of this operation must produce the same result given that the inputs are the same. The operation also has to be stable meaning that the results produced by it should not change in a random way. For instance, the results cannot be based on some random number generation or be influenced by the current time of invocation. However, it is acceptable that the results change with time. For instance, it is acceptable to cache data that is editable by the user.
Cache
To re-iterate, the idea in caching is to avoid the computation again by storing the results of the first computation in some place. So where do we store the results? The answer is that we store it somewhere from where we can easily retrieve them again when needed. This place is the caching repository or in short cache. Hence the cache is the place you goto when you want to
- store results
- retrieve them in a future call.
Cache Key
We have already said that the computation performed by the “cached operation” produces a result that is only dependent on the input parameters and nothing else. Hence by using the input parameters as the key we should be able to retrieve the results of the previous computation without repeating the entire operation once again. This key that is dependent on the input parameters for the operation is called the cache key. The results are stored in the cache using this key. They are also retrieved using this key.
How is Caching implemented?
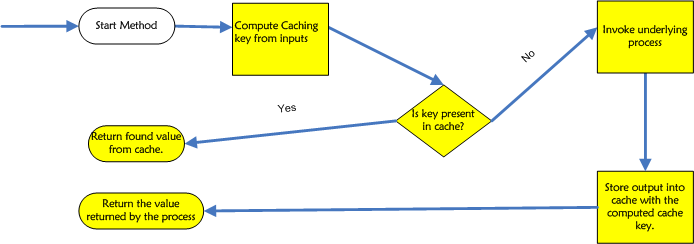
This is best illustrated with an example. Consider the diagram below:  The client makes a call to a complex operation. This call is intercepted typically by a caching interceptor which computes the key from the input parameters and queries the cache with the key. If a value is found in the cache it is returned back to the client thereby bypassing the call to underlying method. Otherwise, the complex operation is invoked and its results are cached into the cache. The results are then returned back to the client. Thus the cache gets updated for future requests.
The client makes a call to a complex operation. This call is intercepted typically by a caching interceptor which computes the key from the input parameters and queries the cache with the key. If a value is found in the cache it is returned back to the client thereby bypassing the call to underlying method. Otherwise, the complex operation is invoked and its results are cached into the cache. The results are then returned back to the client. Thus the cache gets updated for future requests.
Pro-Active and Reactive Caching
The above diagram illustrates reactive caching wherein the cache is only populated on the first request. The cache would never be populated if there had been no requests with the particular input parameters. A second approach is Pro-active caching where the cache is populated actively by some agent running in the background. The results are returned from the cache. A combination of both pro-active and reactive caches are also possible. In this approach, the cache is populated pro-actively. When an actual request is made, the cache is first checked to see if it contains the data that needs to be returned. If the data is found it is returned. Else the cache is first populated reactively as before and returned.
When to use What kinds of Caches?
Pro-active caching works well in the following cases:
- The total number of items in the cache are limited - in other words the total number of cache keys are finite. This is a corollary of another caching axiom - dont use caching when the memory requirements are expected to be very high.
- During the life of the application, it is expected that all of the items in the cache are likely to be used at one time or the other.
- Example of pro-active caches can include caches of all the states within a country, cache of the postal codes etc. Reactive caching is more suitable when
- The cache can potentially have a lot of combination of cache keys.
- The operation is potentially invoked with a vast variation of parameters during the life of the application
- Reactive caches include caches of all transactions for a particular customer, account information etc. This kind of information tends to be too large to be cached pro-actively. The queries against these kinds of information also tend to be arbitrary. For instance, there might be a lot of accounts whose transactions would never be queried during the life of the application and hence it would be wasteful to cache this kind of information.
The Issues involved in using a cache - A Balancing Act
The use of caching, like any software strategy, tends to become a tight rope walk dictated by a few parameters which need to be considered carefully. The biggest problem with caching is that of “cache staleness”. What this means is that the caches can potentially contain data that has since been updated at the source. Hence the data retrieved from the cache becomes stale data and unfit for serious applications. Example: Let us say we are caching account balances. The balance has got updated into the database afterwards thereby resulting in stale data in the cache. This problem tends to get compounded if the data at the source changes frequently. Hence the following observations prevail:
- Caching is easy to implement for “static data”
- Caching for data that changes frequently can only be non stale if all updates to the data go through the caching layer. The second point above is interesting. If all the access to the data is accomplished thru the cache, then the cache would automatically be non stale. Hence isn’t it sensible to keep the cache as close as possible to the source of the data? The answer is a little moot because the whole point of caching is to optimize on the operation. Often the most expensive part of invoking an operation is the network overhead of making this call. If we want to avoid the network overhead, it makes sense to cache the data as close as possible to the consumer of the data and not the producer of the data. Reconciling these two apparently contradictory requirements constitutes an important step in optimizing the cache.


Comments