3 min to read
The n+1 selects problem..

 A few years ago, one of my numerous job sojourns took me to an interesting project at a telecom company. I was a developer then - as I would like to think of myself today as well - and had to maintain code that connected to numerous databases and published various services. In one of the C++ classes, the code issued a database query that obtained a set of rows from one database table - let us call it T1. It then looped through the result set and for each one of the returned rows, it invoked another query to do some checks. The query obtained stuff from another table T2 which had T1’s primary key as a foreign key. The code intrigued me at that time since I was somewhat mystified as to why the developer did not do a database join to obtain the results from both T1 and T2 at the same time. Instead, he was executing a query on T2 for each of the rows obtained from T1.
A few years ago, one of my numerous job sojourns took me to an interesting project at a telecom company. I was a developer then - as I would like to think of myself today as well - and had to maintain code that connected to numerous databases and published various services. In one of the C++ classes, the code issued a database query that obtained a set of rows from one database table - let us call it T1. It then looped through the result set and for each one of the returned rows, it invoked another query to do some checks. The query obtained stuff from another table T2 which had T1’s primary key as a foreign key. The code intrigued me at that time since I was somewhat mystified as to why the developer did not do a database join to obtain the results from both T1 and T2 at the same time. Instead, he was executing a query on T2 for each of the rows obtained from T1.
I did not know it then but I was staring face to face at the (n+1) selects problem! This is the Loch Ness Monster that has devoured a lot of apps in its time and continues strong in many an enterprise!
Problem statement
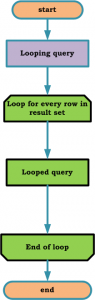
Imagine a somewhat heavy process that returned a set of rows in response to a query. If for each of the rows returned, we are invoking another heavyweight process to obtain some information about them, then we are supposed to be in the midst of the (n+1) selects problem!
Let us illustrate this with an example. Imagine a CRM system that returns a set of customers in response to a query. Let us say that for a particular query Q1 (Ex: get all customers whose last name is ‘SMITH’) the CRM system returned 50 rows with customer Ids from C1 through C50. Now for each of the 50 customers returned, we need to obtain account details information. We first issue a query Q2 that would return all the account details for customer C1. Then we issue a second query for customer C2 and so on till we get to query Q51 that returns account details for customer ID C50. Quite clearly, we have issued 51 queries - the first customer query and 50 account queries for processing the request. If the code base is liberally sprayed with this kind of epidemic, you can imagine how responsive the system would be! The first query Q1 is what I would call a “looping query” and the second queries (Q2 thru Q51) are looped queries i.e. queries that are executed in a loop created out of the result set of the looping query.
If we say that the (n+1) selects problem is an impediment to optimization, we would have understated the obvious! I would like to state here that this problem is not constrained to databases alone although it is prevalent and is readily recognized there. It can be in any kind of enterprise system. We would discuss this more as we go.
Causes & Mitigations
ORM
Most instances of this epidemic have their origin in Object Relational Mapping (ORM) systems. The purpose of ORM is to abstract out database interactions from the core code. Hence the application code deals with entity objects that are manufactured by the ORM system. These objects may spark other queries if certain methods in them are invoked by the application code. Let us go back to the Customer example and define a Customer class that has associated accounts (instances of Account class).
Look at the following code:
public class Customer {
private String id;
// other stuff. with getters and setters.
private List<Account> accounts;
// getter and setter for the list of accounts.


Comments