5 min to read
Services at the cutting edge

We have been working with a client to develop a cutting edge (no pun intended) Point of Sale (POS) system. The key differentiator is to work offline - especially in geographies where internet connection is unreliable. Our solution was to deploy services at the edge (the store) and the cloud. The store services will need to have the same functionality as the ones in the cloud.
We wanted the edge to deflect to the cloud when internet is UP and running but still store a copy of the entity locally so that even if the internet were to go down we should be able to work with the local copy. All stores need to update themselves with the latest copy of the entities so that the customers can theoretically find their entities (such as Orders) in whichever store they may care to go.
Some Design Questions
A lot of questions arose in the design of these services. Some of them are posed below:
-
Should the cloud service be intrinsically different from the store service? Or can we run the exact same service in both the places?
-
How do we make sure that entities are modified reliably? For example, let us take an Order. The Order goes through certain states such as OPENED, SHIPPED etc. How do we make sure that these state transitions remain the same in all the versions of the order across the cloud and all the stores ?
-
Since the logic of the cloud synch is complex, how do we make sure that all services behave consistently? For example, an Order service must have the same logic as the User service with respect to cloud synch. In short, how do we make sure that we extract this logic out of the individual services into a common layer?
-
Quite clearly, the deployment architecture will vary between the cloud and the edge. We may have a zillion micro services deployed separately at the cloud. (I am anyway opposed to one service per deployment irrespective. Se my notes on modulith architecture for example) But we cannot afford to replicate such a complex system at the edge. So how do we deploy the same service differently depending on if it is the edge or the cloud?
Design Choices
As we mulled over these questions, we made a few design choices:
- First and foremost, the exact same service code must run in both the cloud and the edge. This obviates the need for logic replication.
- Services must be developed without awareness of how they are deployed. We need to build them as non-deployable shared libraries which can be deployed in multiple ways. The deployment choice can potentially vary between cloud and edge.
- All entities are managed using a workflow. There is a create() method that creates the entity. ALl other modification (HTTP PUT) operations are modeled as events. A state machine drives these modifications and effects State transitions. This is similar to an event sourcing model where we would be able to re-create all the entity changes by replaying the events.
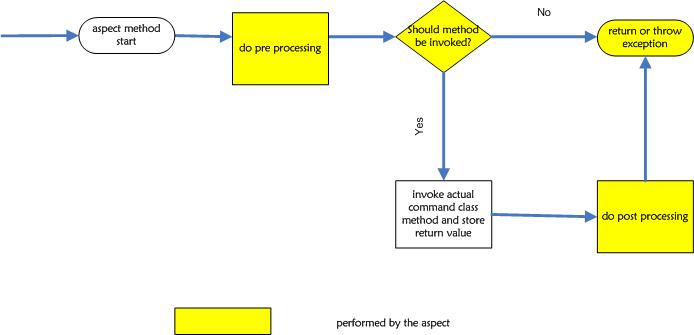
- Services must not contain synch logic. All the synch logic is extracted to an interceptor which is introduced before the service call. This interceptor will take care of service synch.
- Services must be coded to be completely unaware of transport. The same service must work whether it is invoked via HTTP or any other mechanism.
- We should use a queueing technique to handle disconnected situations. When the internet is down, it is not possible for the edge to communicate with the cloud. So it must process the request locally and keep this request in a queue so that the request can be replayed to the code when the internet gets connected. The same technique is applicable to update all the stores from the cloud as well.
Detailed Design & Implementation
We have used the Chenile framework to implement the micro services. The design patterns advocated there are applicable for this problem. Chenile services are developed and deployed indepedently. So, it is possible to vary the deployment architecture between the cloud and the edge.
The Chenile State Transition Machine enables a consistent way of replaying events in the lifecycle of all entities.
We have used MQ-TT to address the problem of messaging over unreliable networks. We are looking for alternatives to MQ-TT brokers. Qos Level 2 of MQTT seems to fit our needs to a tee. Currently we are experimenting with EMQX for the MQ-TT broker. We are also using HiveMQ for testing our MQ-TT code in unit and integration test cases. I will add some details on our testing strategy in a separate article.
Chenile services can be invoked using multiple transports. We added support for MQ-TT. Chenile last mile interception can be used to intercept requests so that we don’t have to write the synch code in every service. We developed a Cloud Edge Switch to handle this requirement.
Next Steps
We need to subject this architecture to some merciless Performance testing. But we are hoping that if MQ-TT scales well, this architecture must scale well. We are betting on the fact that if MQ-TT can scale to IoT (Internet of things), our requirement is certainly not more substantial.
The rest of the architecture is achieved using a few Kilobytes of Java code which we don’t think must detract from performance.
We will keep you posted
There are lots of side-alleys that got explored while we were developing this code. We will write more articles on some of those separately.

Comments